

Salary Caps and Chaos: Examining Parity and Predictability Across Sports
/By: Mike Imburgio
“This isn’t baseball or football, or basketball…we have a very important analytic. It’s the score.” -Bruce Arena, winner of the 1974 World Lacrosse Championship
Soccer is beautiful chaos. It is players working together to weave patterns in line with an overarching plan, but simultaneously reacting to moments influenced by an incredible number of rapidly changing factors. When the chaos lines up perfectly, it’s like those players share one mind and create a product greater than the sum of its parts. Relatively infrequently, that beauty and chaos influence the score.
It is not, as Bruce hinted at, a series of well-defined sequences like baseball or football, or a high-scoring game where decisions often immediately influence the score like basketball, or stretched across a season of 84+ games like hockey. In this article, we’ll take a look at what that means for sports analytics.
Quantifying Chaos Across Sports
Okay, Bruce. Let’s roll with it. The score is the most important analytic. It tells us who won, and winning is what gets trophies. Can it tell us who will win in the future - who’s most likely to win enough that it results in a trophy?
Let’s pause quickly and acknowledge what is obvious to the analytics nerds, even if it isn’t as obvious to Bruce: the scoreline of a game does not predict the future as well as more advanced measures like expected goals or goals added, or even shots for and against, which we’ve shown (not at all for the first time) in our previous replication project article.
But every sport has a score, and to fairly compare across sports, we took a look at how well previous score lines predict future results at any given point throughout the season. We used the same method as that previous article - we took the difference in scores during the season at each game and examined how well it correlates with results (wins or points, depending on the sport) for the remainder of the season.
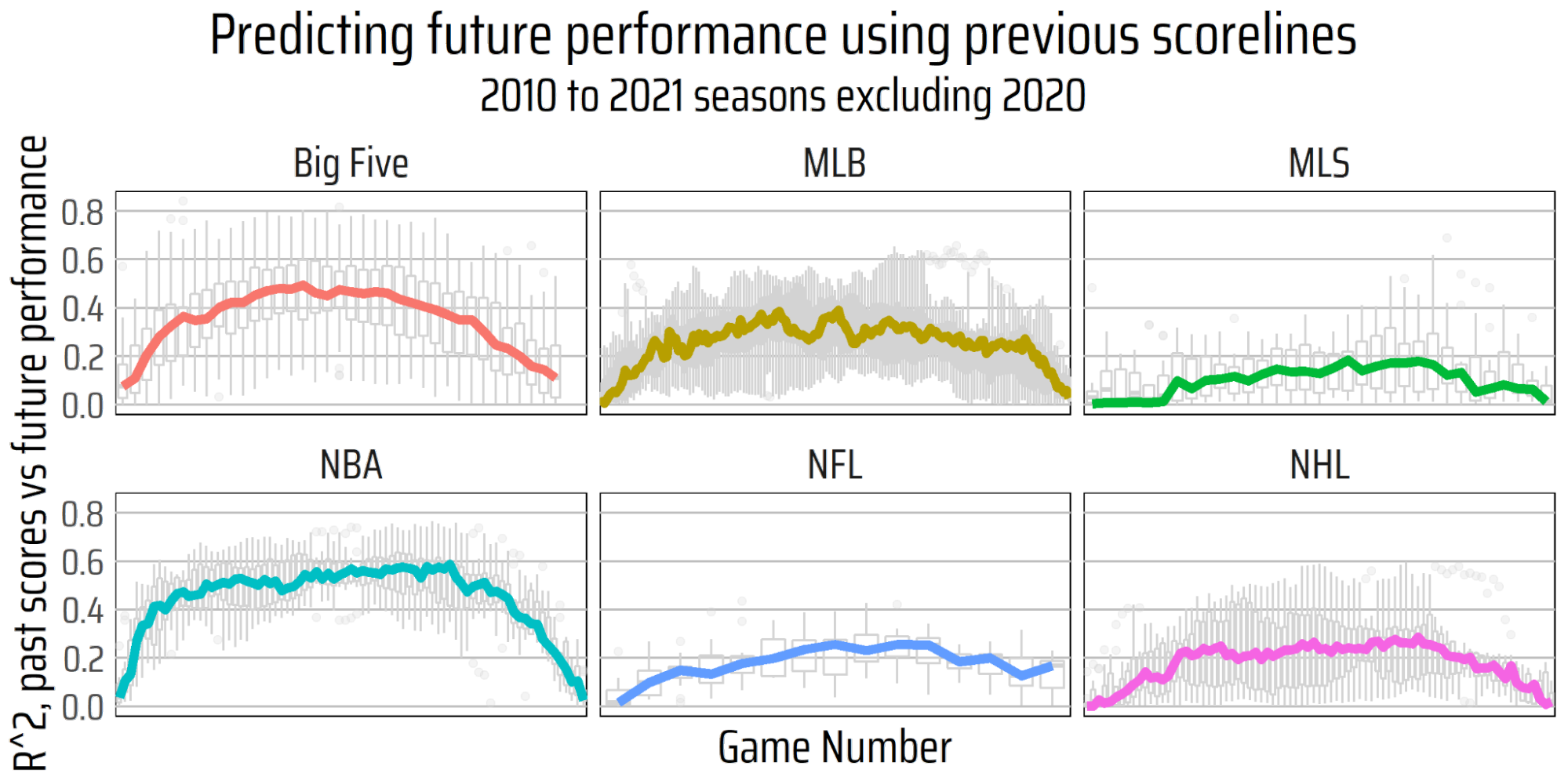
To quickly sum up how to read these charts: the lines peak towards the middle because that’s when there’s lots of data on both previous performance and future performance. The higher the peak of the curve, the more we can use past team performance to judge future team performance.
The curves are a bit ugly due to random variation, even over the course of 10 seasons, although we can see some clear patterns here. To smooth out the curves a little and eliminate some of that random variation, we can bootstrap a bit (randomly sample and rearrange seasons to increase our sample size):

There are a few things to note here immediately. First, across soccer leagues, the amount of chaos varies: the Big Five European leagues show a much clearer relationship between past goal difference and future points per game than MLS, which we’ve found before. In fact, previous results in the Big Five predict future results about as well as in baseball and substantially better than in the NFL.
But there’s another obvious confound here: the number of games across these leagues varies drastically. The more games we have in the past to measure performance, the better chance we have at using that performance to predict the future. We can account for season length by downsampling - restricting the number of games in a bootstrapped season to the same length as the shortest season in the dataset.

Across a 16 game season, the Big Five is about as predictable as basketball and football, while baseball ends up the least predictable. Soccer sure isn’t baseball, Bruce was right about that.
As it turns out, across a short span of games, trying to swing a piece of wood at a ball the size of a fist moving incredibly fast is more chaotic than soccer, especially compared to the Big Five. It makes sense when you think about it - the difference between the batting average of your Average Joe and Shoeless Joe makes little difference over the course of 16 games, and a batting average over 16 games is not very stable. But over the course of a 162 game season, a batting average is informative and it makes a huge difference to the team.
Hockey is similar - it is in many ways very soccer-like. It’s low-scoring, team-oriented chaos, on par with MLS unpredictability over the course of a short stretch of games. But an 82 (and now 95) game season means there’s enough of a sample for patterns to emerge that allow for past results to better predict future results.
Also notable is that, across the American leagues, the higher scoring sports - basketball and football - are the ones that are the most predictable based on previous results when season length is controlled for. Lower scoring sports seem generally more chaotic and less predictable based just on score lines. The Big Five leagues, though, buck that trend hard.
So soccer isn’t baseball, or basketball, or football, or even hockey. The biggest European leagues end up far more predictable than MLS, so soccer isn’t even always soccer when it comes to this kind of thing. There’s more to it than just the sport itself.
Parity Influences Predictability
In our past article, we linked the predictability of a league to the disparity in team strength within a league, operationalized with the Gini coefficient. The idea is simple, at its heart. In a league where teams are of similar strength, past score lines don’t always tell us who the ‘better’ team was, because the games are closer and the margins are finer, so it’s less likely that the ‘better’ team wins the game. In leagues where some teams are clearly more dominant than others, it’s easier to see the patterns emerge from past performance.
We found that this is the reason why the Big Five are so much more predictable than MLS - the gap between the haves and the have-nots is so much wider that it becomes much easier to tell how the rest of the season will pan out. Here, we can see that’s true even over a 16 game span.
We took another look at this idea, first to replicate our original results over a longer span of seasons, and second to see if this pattern exists in other sports.

In every league other than the NFL, we can see fairly strong relationships between the disparity of team results within a season and the predictability of future results from past scores. So, why is the NFL different?
First, it should be noted that ten data points are not exactly ideal for testing a correlation, although it was enough to detect the relationships elsewhere. Another reason could be that the length of the season limits the utility of the Gini coefficient. In other words, there might not be enough games to see disparity influence standings to the point that Gini can be fully sensitive to season-to-season changes. The NFL is clearly showing the most disparity here, though, with the highest Gini coefficients every season.
Again, we can account for these season length differences by downsampling, as described earlier. Using this downsampling procedure, we can examine how much of these differences in predictability across leagues, not just within them, can be accounted for by team disparity. This also increases our sample size and the range of these variables to better detect a relationship.

Disparity accounts for a lot of the predictability, apparently. When viewed across all of these leagues, parity among teams within a season accounts for 89% of the variance in predictability once season length is controlled for.
There’s still clear delineation in parity across leagues, though. Some of this is almost certainly due to differences between the sports themselves, as described earlier. But again, the consistent differences between MLS and European leagues point to the idea that disparity in team performance within a sport is also dependent on economic disparity within a league. On top of that, these two things - the nature of the sport and economic disparity - probably interact.
Stretching Spend Across Leagues
In American sports, teams operate under salary caps. When they’re bought out by a billionaire, that billionaire can’t just pump the entire team full of money and buy a top tier replacement for every player. They have to pick and choose which players and positions to allocate that big spending towards.
In football, the quarterback is king. Every offensive play starts with the QB, and the result is that the QB has a disproportionately large amount of influence on their team’s performance. The new billionaire owner can almost guarantee their limited big purchase will be worth it if they target the top quarterback.
In basketball, there isn’t necessarily one position that dominates others like this (if there are even positions anymore at all), but a single player or two certainly can. Basketball teams can, and do, build entire offenses around feeding a single player the ball who they’ll expect to carry their team. And sometimes, they win championships doing it.
These descriptions are admittedly reductive. There’s more to building a roster in the NBA or NFL than just one player. But contrast the influence of one player in those sports with in soccer, where it’s not as easy to guarantee that a single player can get on the ball enough to take over the game, let alone in a position where they can directly influence the score. Or hockey, where the second line of offense is nearly as influential as the starting line. Or baseball, where your best hitter spends most of the game taking a seat and waiting his turn, which will probably come just three or four times a game, while every other player takes their turn in between. Imagine if every time Giannis passed the ball, he had to wait for all of his other teammates to touch it before he could get on the ball again - that’s basically what the batting order does to spread offensive influence around a baseball team. Betting big on a player or three is much more impactful in some sports than in others.
European sports don’t work this way. Billionaires can buy out a team and throw money at every one of their starting eleven. FIFA might pretend to care sometimes, and do something about it in the future eventually, maybe. Without those restrictions on spending, we see less parity (and more predictable results). That reduction in parity means that barring a new billionaire buyout, the rich get richer and the poor get poorer:

This concept means, theoretically, that we’d see all leagues get more predictable under fewer salary restrictions and less predictable under greater salary restrictions, and that the distribution of team strength would be more equitable under a cap than without it. That’s the whole point of a salary cap, after all - to promote parity. To test this formally, we can look at what happened before and after the NHL introduced a salary cap in 2004.

There is a clear and statistically significant reduction in team disparity (an increase in league parity) following the introduction of the salary cap in 2004. This supports the idea that money plays a large role in disparity across leagues, and that a salary cap reduces that disparity within a sport. The cap worked as intended and the Gini coefficient captured the effect. Of course, not all caps are created equally. A deeper dive into the nuances of different salary cap rules and their effects on parity, while beyond the scope of this article, would be interesting.
Takeaways
So what does it all mean? Is disparity good or bad? Is money the root of all evil and also all trophies? Why do the answers to these questions matter at all?
Some answers are more philosophically important for sports in general. There is an argument to be had that too much parity means too much chaos - if every team is equally matched, you end up with no team that defines an era or becomes a draw for the general public, fewer clear narratives for the soap opera of the season. But obviously, no one wants to watch a game when the season’s outcome is 100% certain - at that point, you might as well just play the game on a spreadsheet. What’s worse, unchecked disparity begets greater disparity. There is, then, some ‘optimal’ amount of parity that allows for the best of both worlds. That amount is also probably a matter of individual opinion, but it’s nonetheless an important factor for a league trying to understand its appeal to its fans.
Some answers are more practically important for analytics. Take, for example, the quote from Bruce Arena at the beginning of the article. In the full quote, Bruce suggests that the score is the only thing that matters, that ‘other analytics’ are a waste of time in soccer. In a likely generous interpretation of what he meant - that goals are what win trophies - he’s of course correct. There are, though, better measures of past performance that are more likely to tell you if you’re going to win a trophy, like expected goals or goals added, as covered in the previous articles in this series and many places elsewhere. But there are also two things that the analyses here make clear:
Any analytic, even the score (especially the score), needs a large enough sample for us to learn anything about what it means for the future. This much we know. But importantly, the size of the sample needed for past statistics to inform us about future performance depends in part on the sport in question. Some sports are more chaotic than others.
The degree to which past performance can tell us about the future performance of a team also depends on the parity (in team quality/team spend) within the league. In leagues where teams are of even quality, even advanced analytics (covered in the previous article in this series) are less informative about the future compared to leagues where the best and worst teams are more clearly defined. At least when it comes to the predictive ability of scorelines, this seems to be a fairly universal rule across sports.
Acknowledgements: This article was the result of lots of collaboration among the ASA community, particularly Eliot McKinley, Sean Steffen, and Tiotal Football.